OllamaChat
Self Hosted AI Chat Platform
A self-hosted ChatGPT alternative that runs entirely on your own machine using Ollama. It can search your documents to answer questions, remember things across conversations, automatically switch to the right model for coding or vision tasks, use tools to search the web, and optionally speak and listen, all without sending anything to the cloud.

Project Details
I built this project to truly understand how AI tools work under the hood, not just use them as a black box. What started as a simple Ollama playground grew into a fully-featured local AI platform. It searches your own documents to give grounded answers with confidence scoring (RAG), remembers useful things you've told it across sessions, detects when you're asking a coding question or sending an image and routes to the right model, runs an agentic tool-use loop for web search and URL fetching, supports extended reasoning with think blocks, and offers optional voice input and output via a locally-hosted speech service. Everything runs on your own hardware: no subscriptions, no data leaving your machine.
Results & Impact
Document search directly
Into SQLite using native vector embeddings with no external vector database needed
A multi-stage message pipeline (system prompt → memory → document context → history)
With live streaming
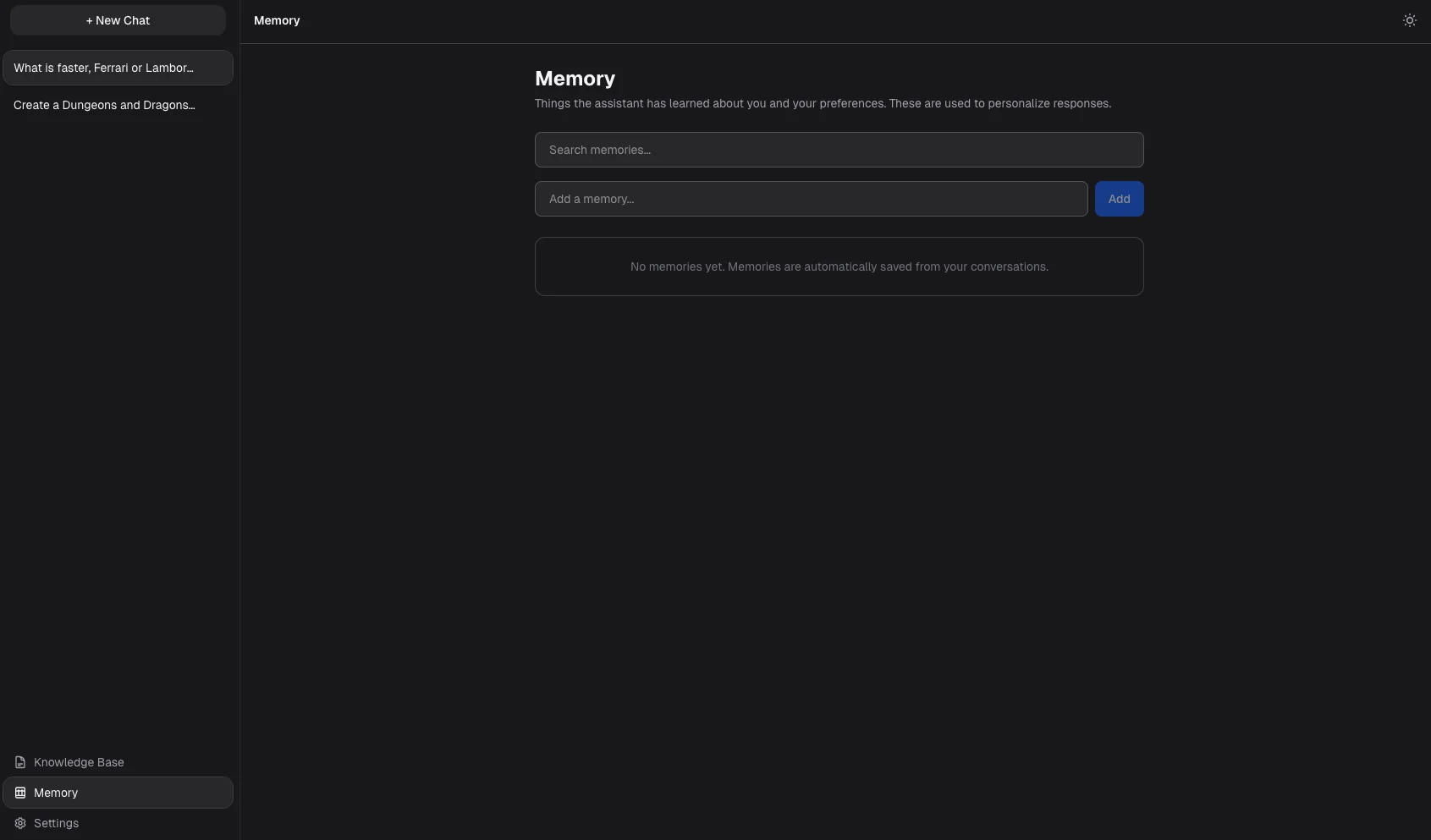
A memory system
That automatically captures, ranks, and recalls preferences and facts across conversations
Smart model routing
That detects coding intent, image attachments, and vision capability to switch models transparently
An agentic tool-use loop
With web search and URL fetching across up to five rounds per turn
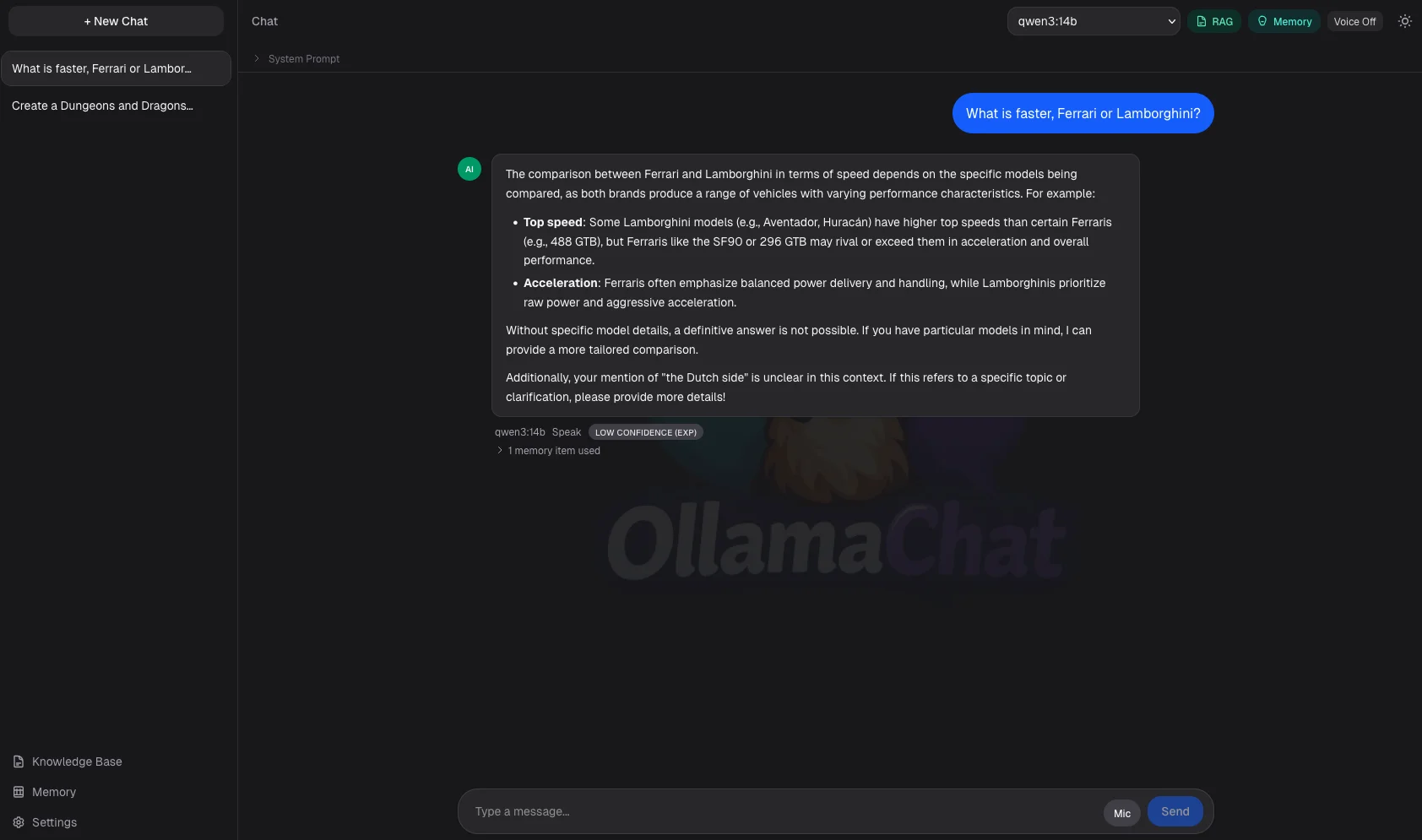
Grounding confidence scoring (high/medium/low) on RAG answers
With source citations
Extended reasoning
With streaming think-block detection and buffering
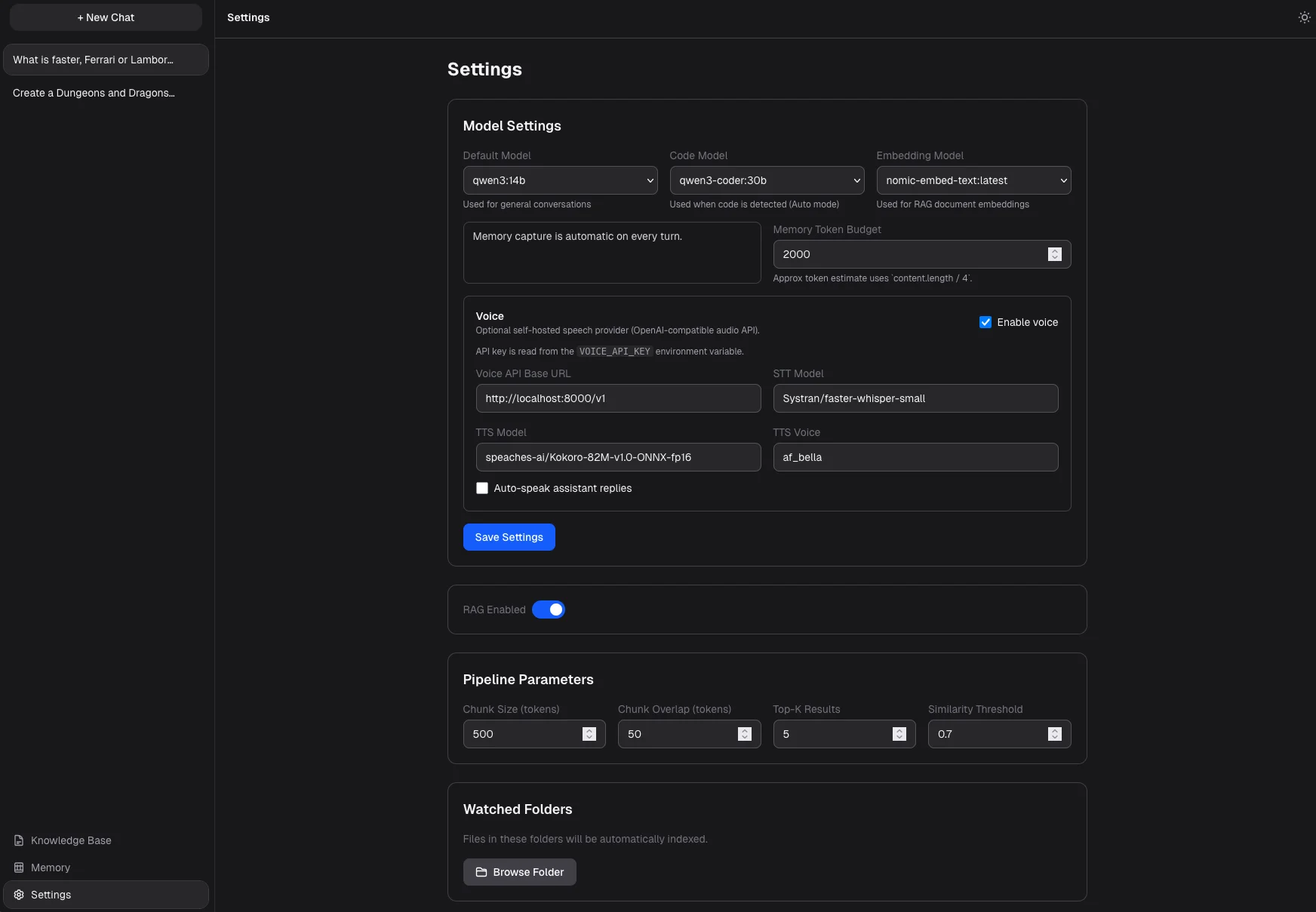
Optional voice I/O
Using locally-hosted Whisper (STT) and Kokoro (TTS) with intelligent sentence splitting
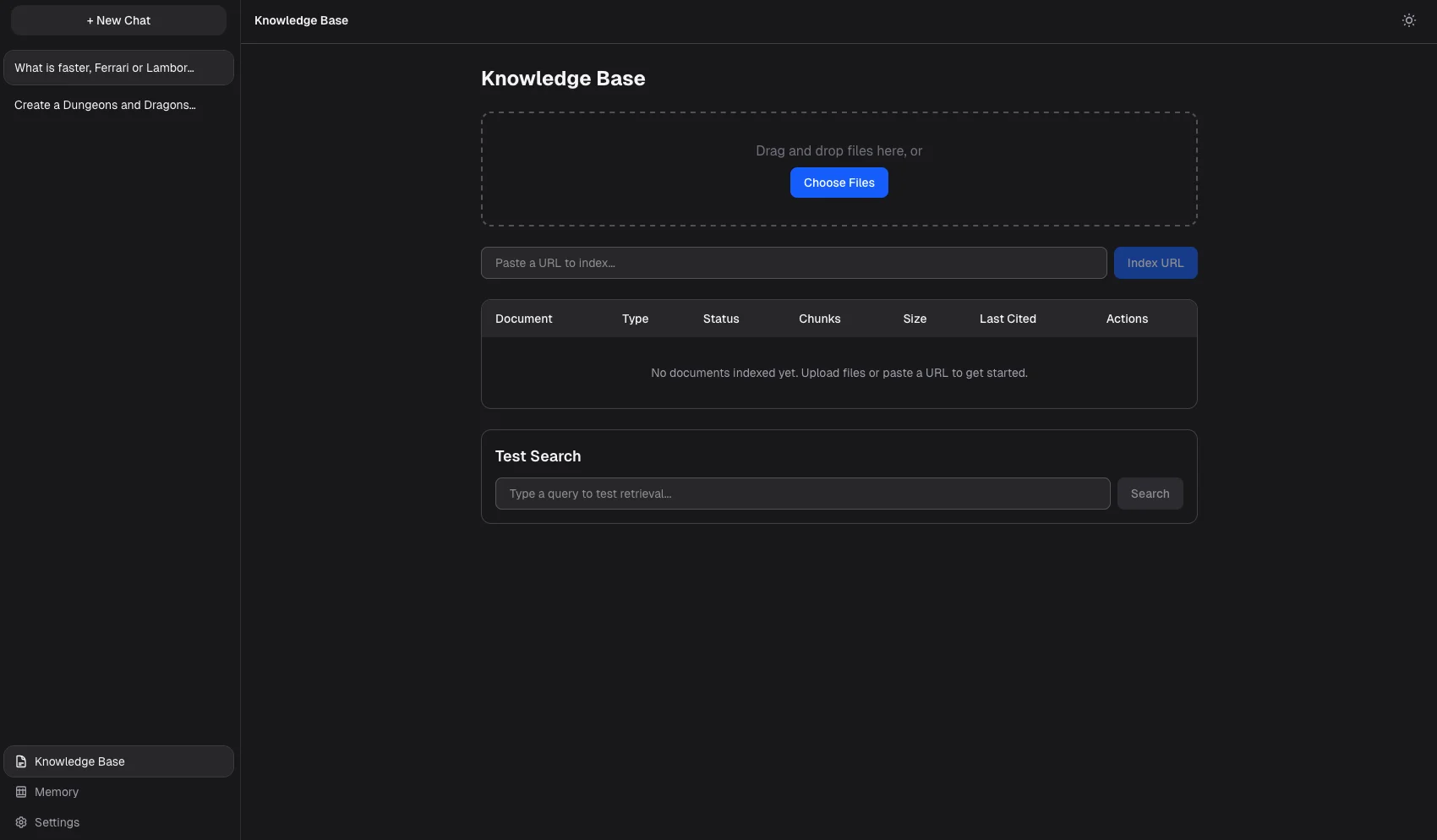
Document ingestion
For Markdown, PDFs, code files, and live web URLs with language-aware chunking
Per-conversation toggles
For RAG, memory, agent mode, and custom system prompts
Challenge to Solution
What had to be solved
Build a self-hosted AI chat app that matches cloud tools in capability while running completely locally.
The hard parts: implementing document search without a third-party vector database, building a memory system that captures useful context without flooding every message with noise, detecting coding and vision intent to route to the right model, adding an agentic tool-use loop, supporting extended model reasoning, and adding voice I/O, all in a clean, fast UI.
How it came together
Document search is powered by SQLite with native vector support (libSQL), so there's no need for an external service like Pinecone.
Every message goes through a multi-stage pipeline: system instructions, then relevant memories ranked by relevance and recency, then matching document excerpts with grounding confidence scores, then conversation history, all streamed live. An agentic loop lets the model call tools like web search and URL fetching across up to five rounds before composing a final answer. Model routing auto-detects coding patterns, image attachments, and vision capability to transparently switch models mid-conversation. The memory system auto-extracts facts per turn, scores them by relevance, recency, and frequency, and supports superseding outdated memories. Voice runs through a Docker sidecar using Whisper for speech-to-text and Kokoro for text-to-speech, with intelligent sentence splitting for natural speech pacing.
Product in Use
Key Features
Chat with any locally installed Ollama model
With real-time streaming responses
Automatically switches
To a dedicated coding model when it detects coding questions
Auto-routes image attachments
To vision-capable models with drag-and-drop and clipboard paste support
Upload documents
PDFs, code files, or web URLs to a searchable knowledge base
Searches your documents
And injects relevant excerpts into every answer, with confidence scoring and source citations
Remembers preferences
And facts across conversations with automatic extraction, relevance ranking, and memory superseding
Agentic tool-use loop
That can search the web and fetch URLs across multiple rounds before answering
Supports extended reasoning
With think-block streaming for compatible models
Push-to-talk voice input
And spoken responses via locally-hosted speech models with natural sentence pacing
Per-conversation toggles
For RAG, memory, agent mode, and custom system prompts
Persistent conversation history
With automatically generated titles
Watch a folder
And automatically index new files as they are added