OllamaChat
Self Hosted AI Chat Platform
A self-hosted ChatGPT alternative that runs entirely on your own machine using Ollama. It can search your documents to answer questions, remember things across conversations, automatically switch to a coding model when you ask coding questions, and optionally speak and listen all without sending anything to the cloud.

Project Overview
Technologies Used
Project Details
I built this project to truly understand how AI tools work under the hood, not just use them as a black box. What started as a simple Ollama playground grew into a fully-featured local AI platform. It searches your own documents to give grounded answers (RAG), remembers useful things you've told it across sessions, detects when you're asking a coding question and routes it to a dedicated code model, and supports optional voice input and output via a locally-hosted speech service. Everything runs on your own hardware no subscriptions, no data leaving your machine.
Challenge
Build a self-hosted AI chat app that matches cloud tools in capability while running completely locally. The hard parts: implementing document search without a third-party vector database, building a memory system that captures useful context without flooding every message with noise, detecting coding intent to route to the right model, and adding voice I/O all in a clean, fast UI.
Solution
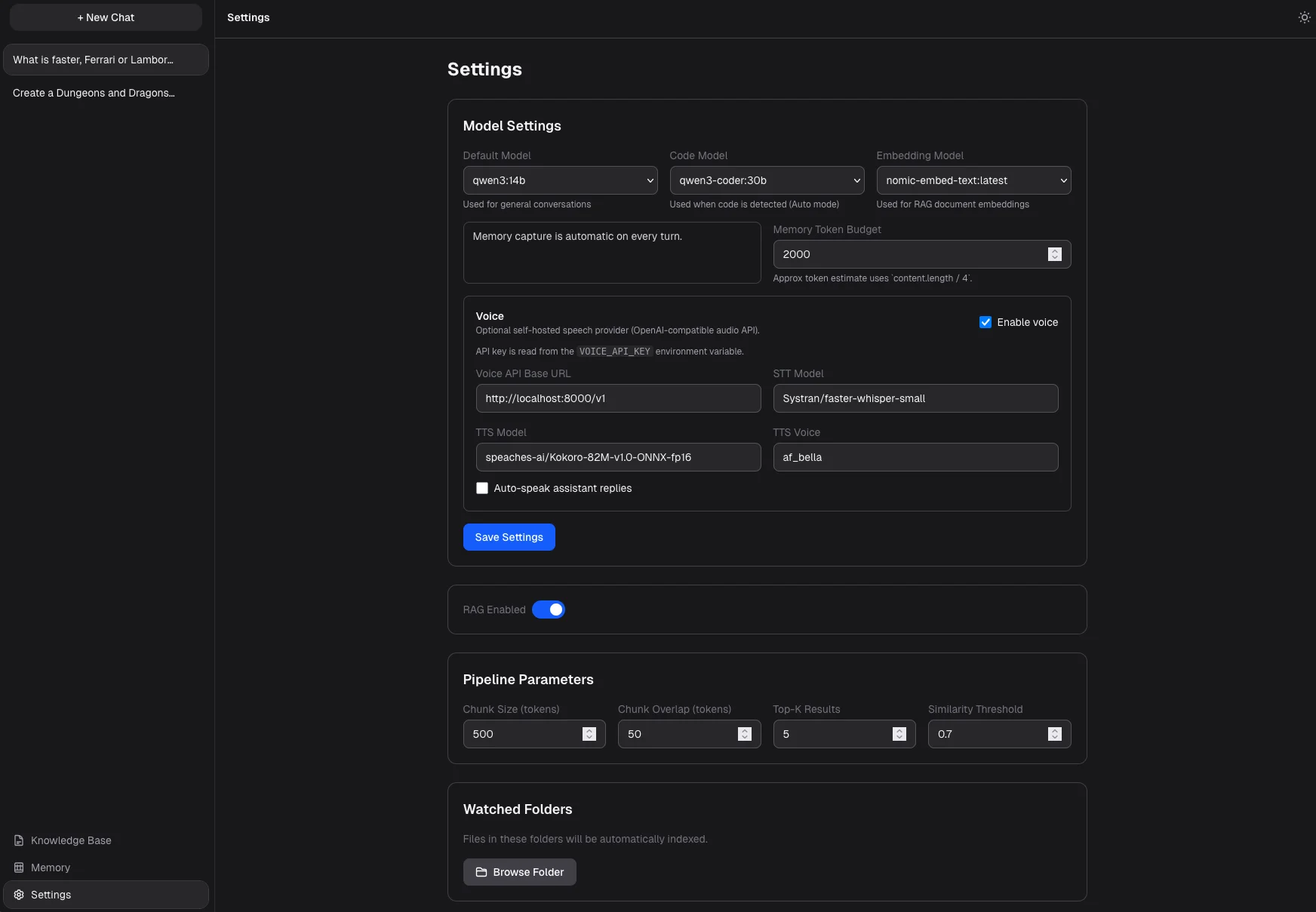
Document search is powered by SQLite with native vector support (libSQL), so there's no need for an external service like Pinecone. Every message goes through a four-stage pipeline: system instructions, then relevant memories, then matching document excerpts, then conversation history all streamed live. Coding intent is detected with regex patterns across keywords, file extensions, and syntax, triggering a switch to a code-focused model. The memory system auto-extracts up to 3 facts per turn and scores them by relevance, recency, and how often they've come up. Voice runs through a Docker sidecar using Whisper for speech-to-text and Kokoro for text-to-speech.
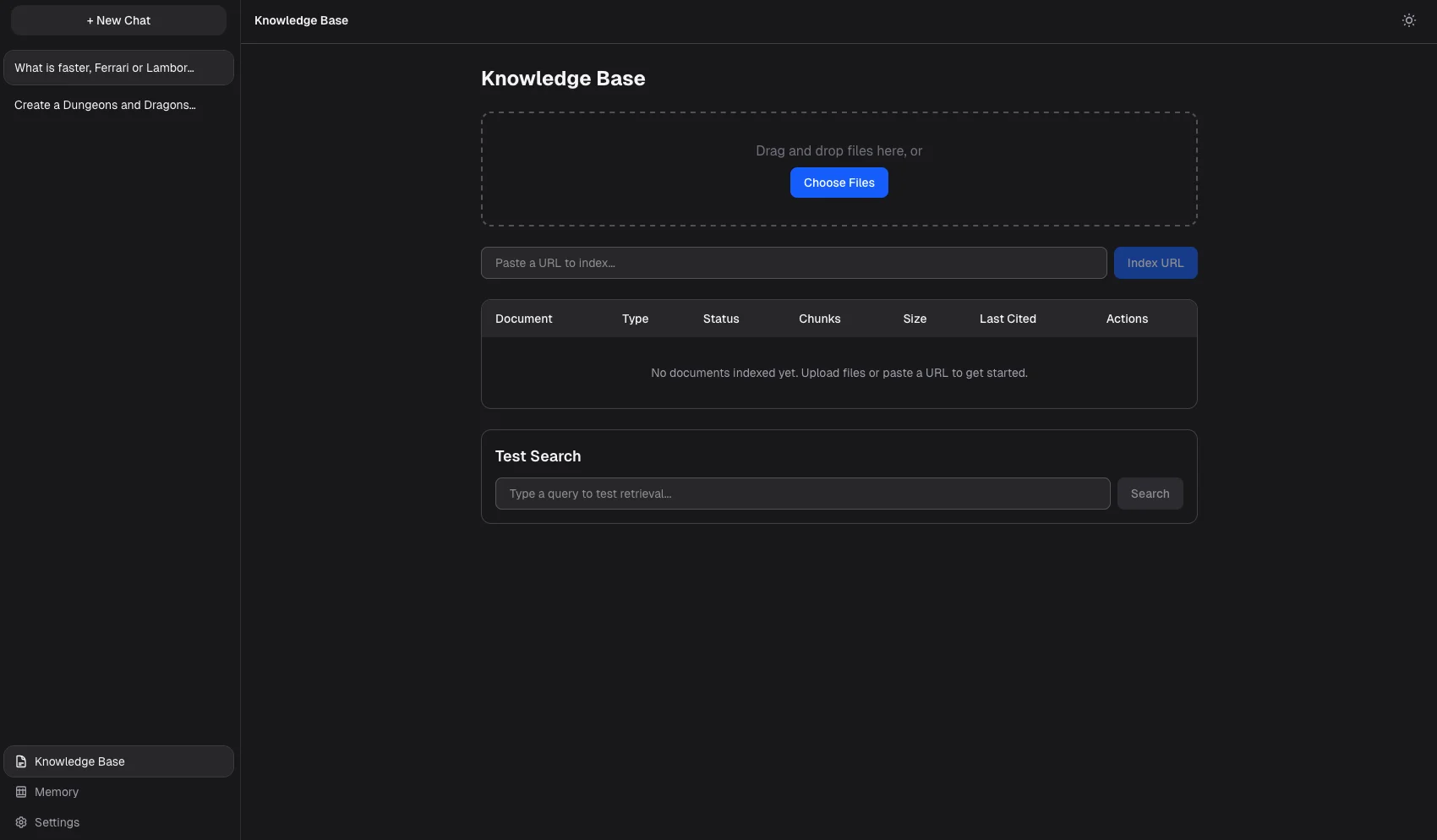
Key Features
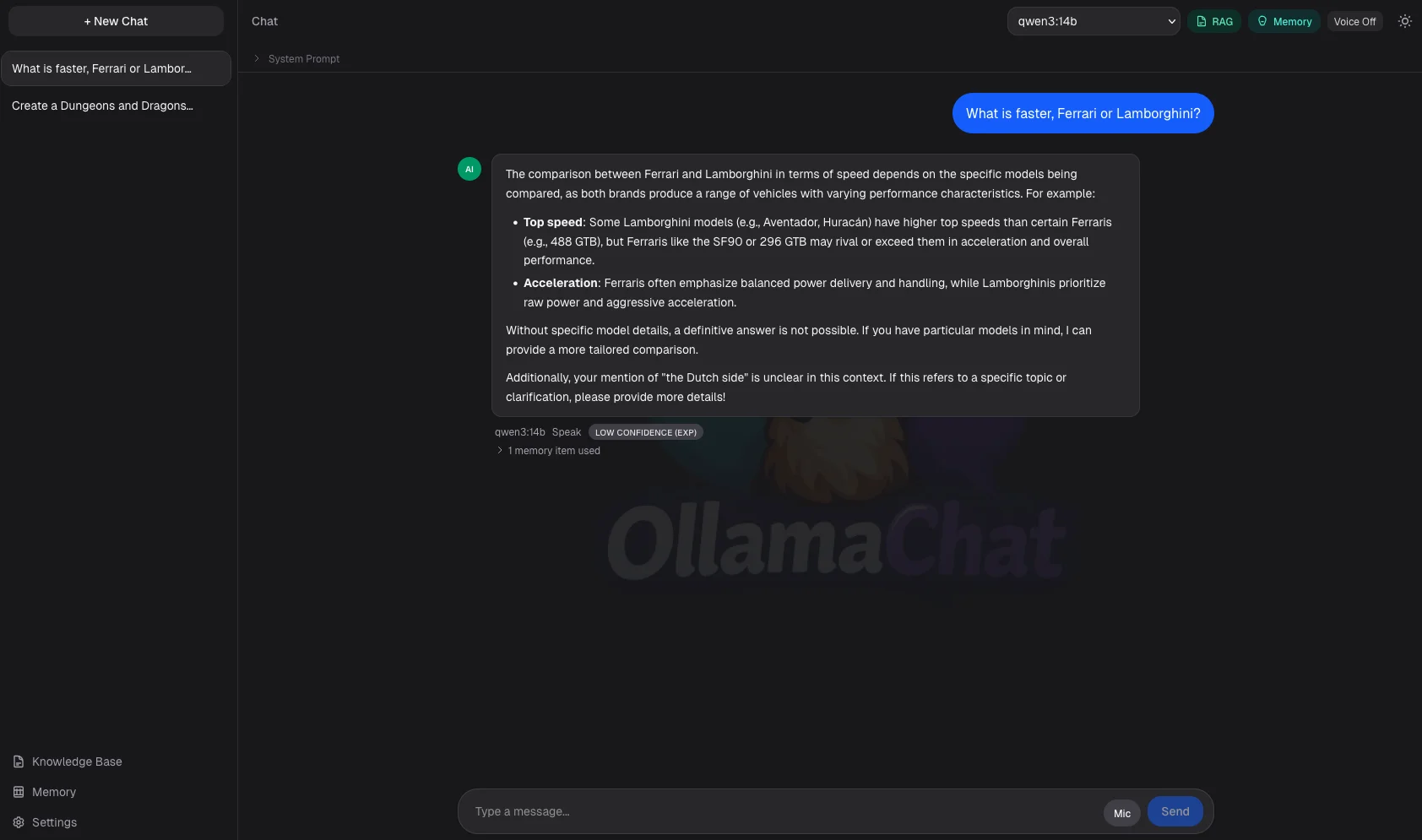
- Chat with any locally installed Ollama model with real-time streaming responses
- Automatically switches to a dedicated coding model when it detects coding questions
- Upload documents, PDFs, code files, or web URLs to a searchable knowledge base
- Searches your documents and injects relevant excerpts into every answer, with source citations
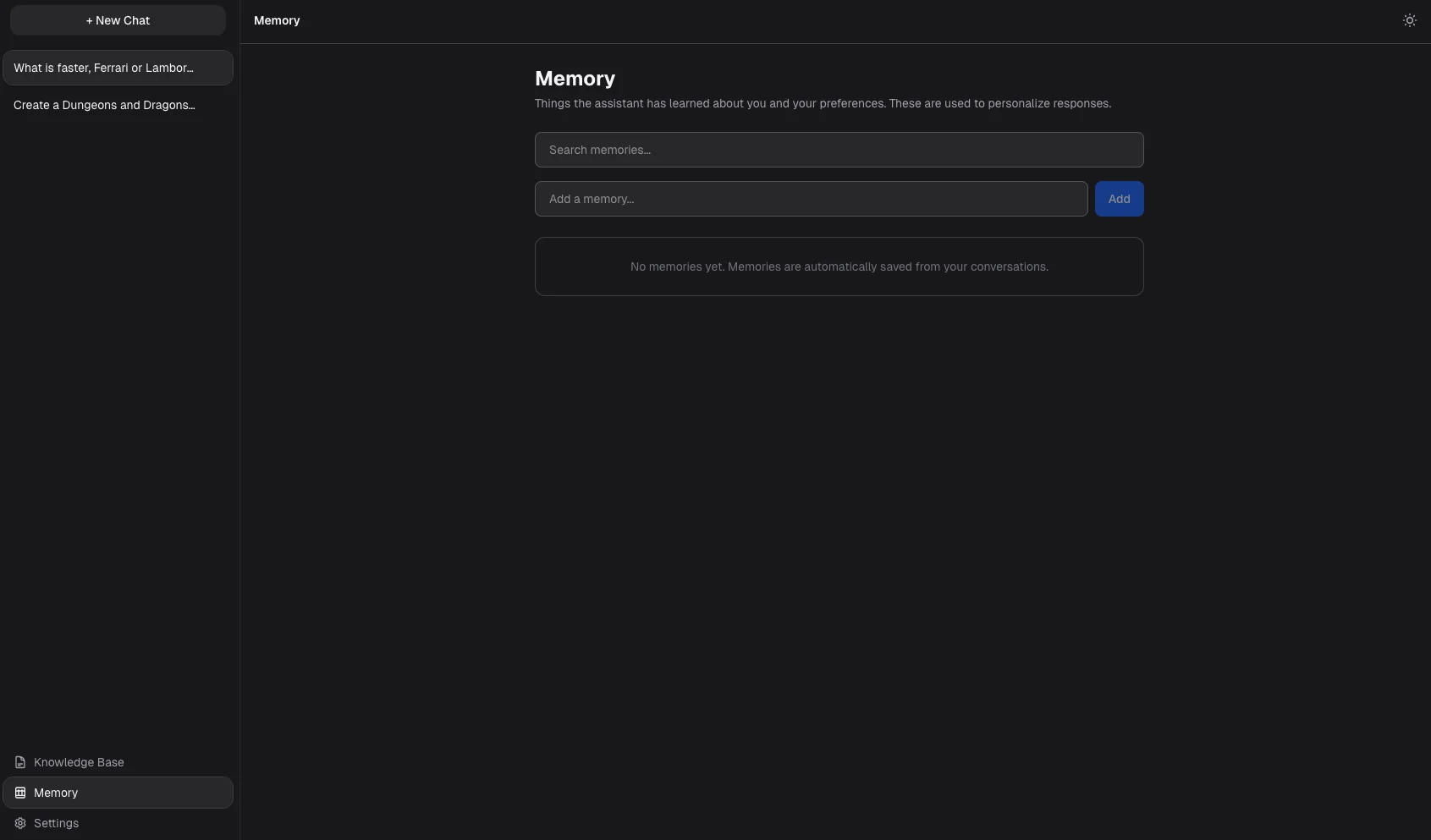
- Remembers preferences and facts across conversations without you having to repeat yourself
- Push-to-talk voice input and spoken responses via locally-hosted speech models
- Persistent conversation history with automatically generated titles
- Watch a folder and automatically index new files as they are added
Results & Impact
- ✓
Built document search directly into SQLite using native vector embeddings no external vector database needed
- ✓
Implemented a four-stage message pipeline (instructions → memory → document context → history) with live streaming
- ✓
Created a memory system that automatically captures and recalls preferences and facts across conversations
- ✓
Built a coding intent detector that transparently switches to a dedicated code model mid-conversation
- ✓
Added optional voice I/O using locally-hosted Whisper (speech-to-text) and Kokoro (text-to-speech)
- ✓
Supported document ingestion for Markdown, PDFs, code files, and live web URLs